트랜스포머 모델을 지도 학습(supervised) 또는 자율 학습(self-supervised) 방식으로 학습시킬 때, 마지막 어텐션 레이어는 자연스럽게 이미지의 의미적으로 일관된 부분들에 집중합니다. 이는 아래와 같이 해석 가능한 어텐션 맵을 만들기도 합니다.
Attention maps from the DINOv1
새로운 unsupervised detection 알고리즘들은 일반적으로 이러한 어텐션 맵을 사용하여 객체를 탐지합니다.
그런데, Attention map을 이용한 탐지 알고리즘을 사용할 때 DINOv1으로 학습된 모델이 DINOv2에 비해 더 잘 작동한다는 것을 발견되었습니다.
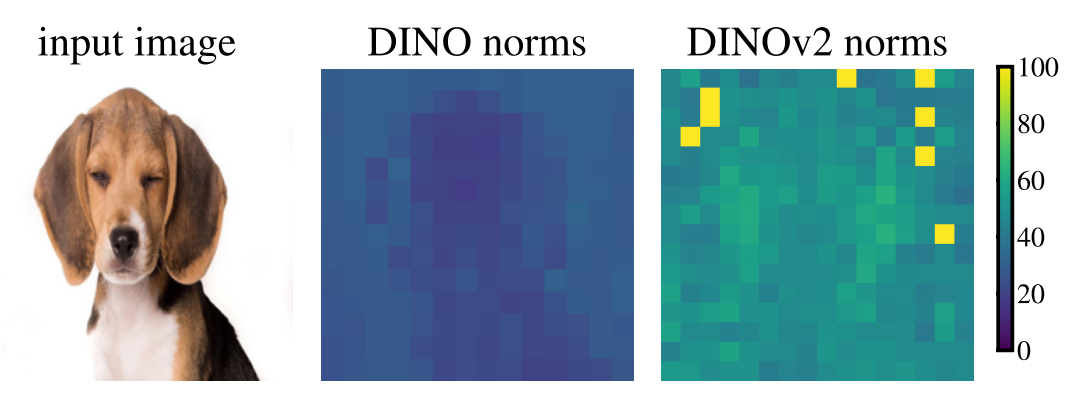
그 이유는 DINOv2에는 대략 10배 더 높은 놈(norm)을 가진 토큰들이 있다는 것이었습니다. 이러한 토큰들은 전체 토큰의 극히 일부였습니다.(약 2%)
패치된 토큰들의 놈(norm) 값입니다. DINOv1에서는 모든 매치가 유사한 놈 값을 가지지만, DINOv2에서는 매우 높은 놈을 가진 패치가 몇 개 있습니다. 이러한 높은 norm의 패치가 주변 토큰과 주로 유사한 위치에 있다는 점에 주목하세요.
이러한 높은 놈의 토큰은 일반적으로 비전 트랜스포머의 중간 레이어에 나타납니다. 또한, 충분히 큰 트랜스포머를 충분히 오랫동안 학습한 후에만 나타납니다.
또한, 이러한 이상치 토큰은 이웃과 유사한 패치에 나타나는데, 이는 추가 정보를 거의 전달하지 않는 패치를 의미합니다. (패치가 생성된 후 임베딩의 코사인 유사도를 계산했습니다. 이상치 패치는 주변 토큰과 높은 코사인 유사도를 가집니다.)
그래서, 이상치 토큰이 포함하고 있는 정보를 이해하기 위해 간단한 선형 모델로 평가해봤습니다. 두 가지 작업에 대해 테스트했습니다. 하나는 선형 레이어를 사용하여 위치 임베딩을 예측하는 작업입니다(트랜스포머를 통해 처리되기 전에 추가됩니다). 두 번째 작업은 해당 토큰에서 패치를 재구성하는 것입니다. 이상치 토큰의 경우 재구성 정확도가 다른 토큰보다 낮습니다. 이상적으로, 토큰이 로컬 패치 정보를 가지고 있다면 이러한 작업은 쉽게 완료될 수 있습니다. 트랜스포머는 고정되어 있고 두 작업 모두에서 선형 레이어만 학습됩니다.
따라서 비이상치 토큰과 비교할 때, 이상치는 이미지에서 원래 위치나 패치의 원래 픽셀에 대한 정보를 더 적게 가지고 있습니다. 반면에, 이상치 패치에서 이미지 분류기를 학습하면 다른 패치에서 학습하는 것보다 정확도가 훨씬 더 높아집니다. 이미지 수준 분류기는 적절한 클래스를 예측하기 위해 전체 이미지에 대한 전역 정보가 필요합니다. 따라서 이러한 이상치 패치는 로컬 패치 정보를 버리고 일부 전역 정보를 학습하려고 한다는 것을 알 수 있습니다.
일반 패치 토큰과 이상치 패치 토큰에 대한 선형 탐침(linear probing)을 통한 이미지 분류. 이상치 토큰은 일반 토큰보다 훨씬 더 높은 정확도를 보입니다.
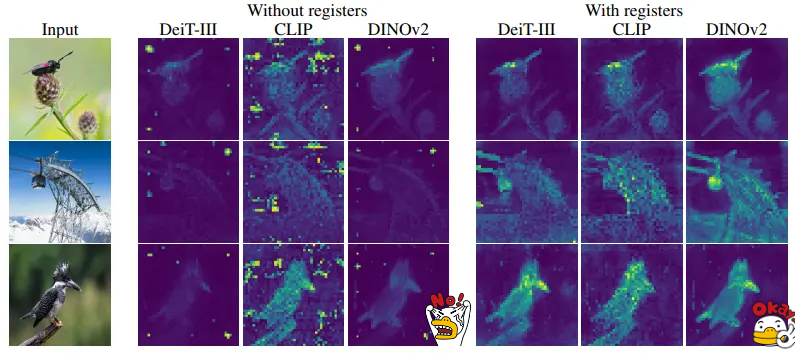
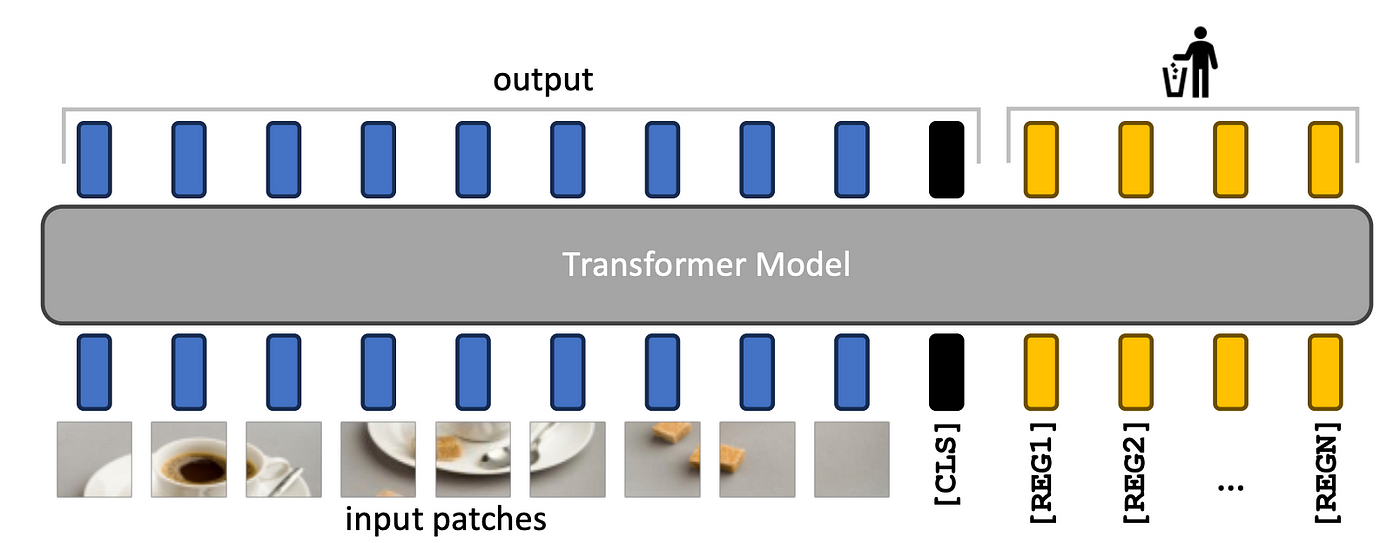
위의 가설을 테스트하기 위해 위 논문에서는 더 많은 클래스 토큰(레지스터라고 부릅니다!)을 추가하고 모델을 다시 학습시켰습니다. 더 많은 클래스 토큰으로 학습된 모델은 이상치 토큰이 발생하지 않고 훨씬 더 부드러운 특징 맵을 가집니다. 이러한 새로운 모델은 Detection ㅅ작업에서도 잘 작동합니다.
Token norms with and without registers
레지스터를 사용한 실험
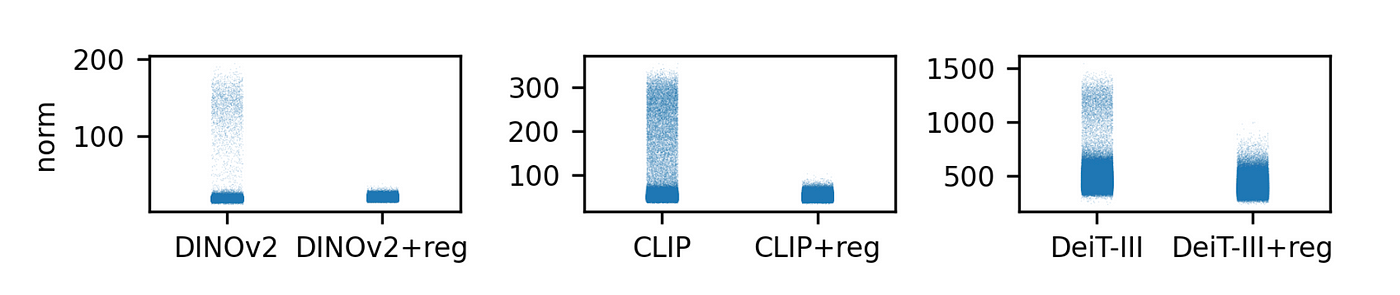
레지스터 토큰이 토큰 놈 값에 미치는 영향: 레지스터 토큰을 사용하면 큰 놈을 가진 패치가 발생하지 않습니다.
Attention maps with additional registers (DINOv2 model)
[CLS] 토큰과 레지스터의 관심도 맵 비교. 등록 토큰은 때때로 피처 맵의 다른 부분을 담당하기도 합니다.
[CLS] token and register tokens attention maps
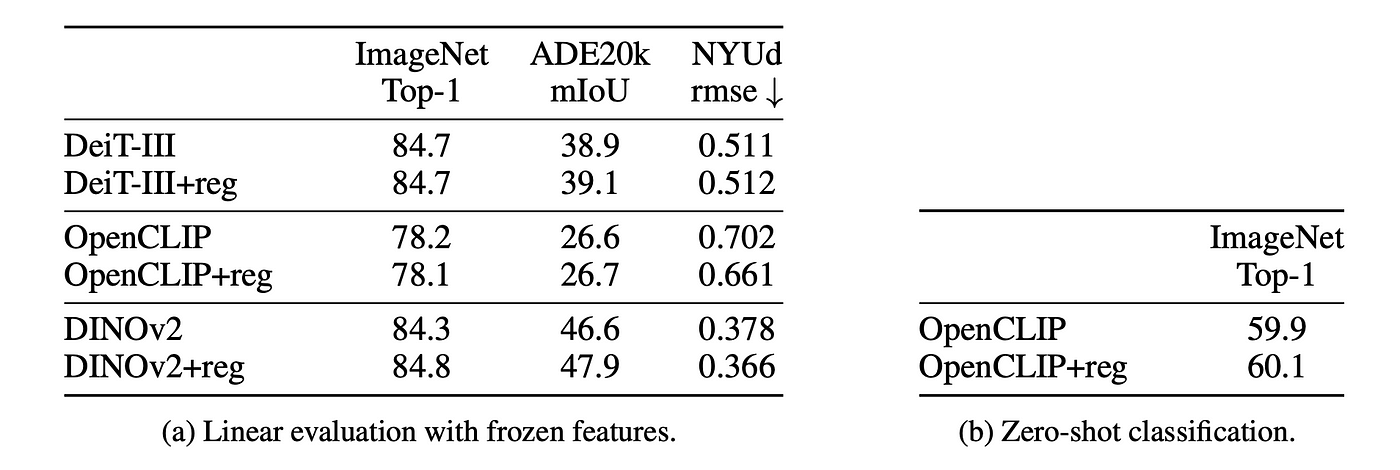
다양한 모델의 다운스트림 성능을 평가합니다.
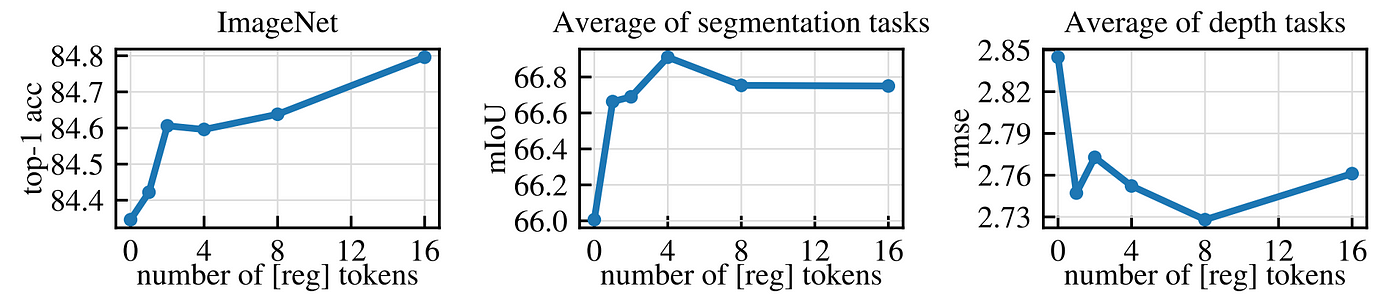
밀도가 높은 작업에는 최적의 레지스터 수가 있는 것으로 보이며, 레지스터를 하나 추가하면 대부분의 이점을 얻을 수 있습니다. 이 최적값은 아티팩트가 사라져 로컬 기능이 향상되기 때문일 가능성이 높습니다. 그러나 이미지넷에서는 레지스터를 더 많이 사용할 때 성능이 향상됩니다. 모든 실험에서 레지스터 토큰을 4개로 유지했습니다.
performance on three tasks (ImageNet, ADE-20k, and NYUd) as a function of number of registers used. While one register is sufficient to remove artifacts, using more leads to improved downstream performance.
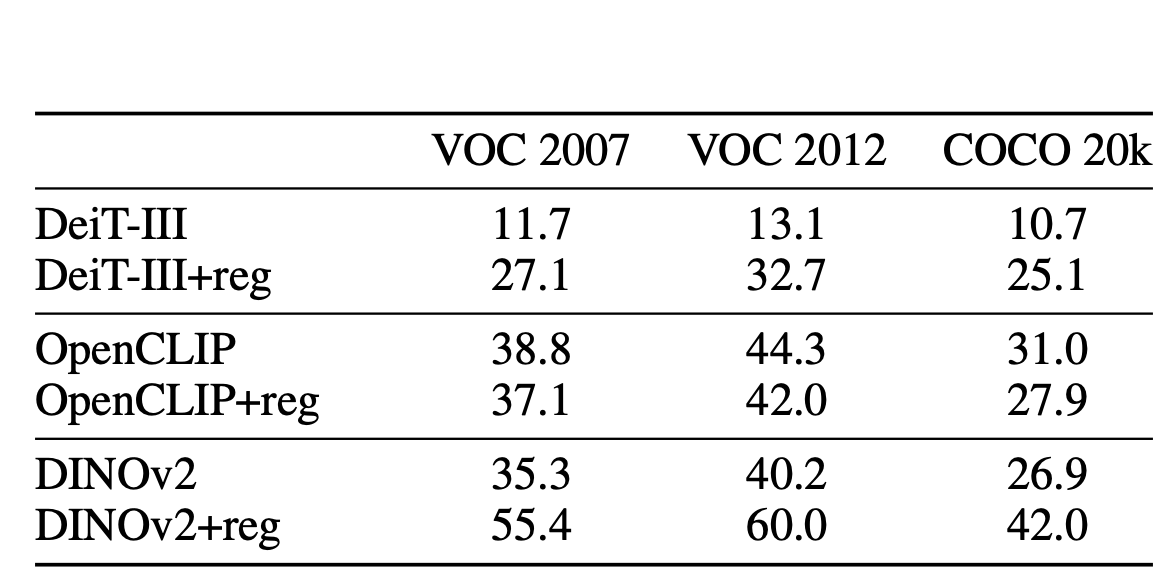
레지스터가 있는 모델에서 비지도 개체 검색의 결과가 개선되었습니다. 저자는 VOC 2007, 2012, COCO에서 다양한 양의 감독으로 훈련된 세 가지 유형의 모델을 평가했습니다.
Results with unsupervised object detection.
Implementation
Timm을 사용하여 토큰을 더 추가하는 방법을 보여드리겠습니다. 먼저 이미지를 패치로 나눕니다.
# define the encoder config
depth=24
num_heads=16
mlp_ratio=4.
norm_layer=nn.LayerNorm
norm = norm_layer(embed_dim)
# initialize the encoder blocks
blocks = nn.ModuleList([
Block(embed_dim, num_heads, mlp_ratio, qkv_bias=True, norm_layer=norm_layer)
for i in range(depth)])
# process in the encoder and normalize
for blk in blocks:
x = blk(x)
x = norm(x) # [2, 4101, 768]