2023. 9. 18. 18:21ㆍ딥러닝
대규모 언어 모델(LLMs)은 프로그래밍 보조 도구와 범용 챗봇 같은 새로운 응용 프로그램을 가능하게 해서 일상 생활과 경력에 점점 더 큰 영향을 미치고 있습니다.
그러나 이러한 응용 프로그램의 작동은 GPU와 같은 상당한 하드웨어 가속 요구 사항 때문에 상당한 비용이 듭니다.
최근의 연구에서는 LLM 요청을 처리하는 것이 전통적인 키워드 검색보다 최대 10배 비싸다고 볼 수 있습니다.
따라서 LLM 서빙 시스템의 처리량을 높여 요청당 비용을 최소화할 필요성이 점점 늘고 있습니다.

대형 언어 모델이 돌아가길 기다리는 우리 모습..
대규모 언어 모델(LLMs)을 높은 처리량으로 서빙하기 위해서는 충분히 많은 요청을 한 번에 배치해야 하며, 기존 시스템도 높은 성능을 위해선 이러한 능력이 필요합니다.
그러나 기존 시스템은 도움이 필요합니다. 왜냐하면 각 요청에 대한 Key-Value 캐시(KV 캐시) 메모리가 매우 크고 동적으로 증가하거나 축소될 수 있기 때문입니다. 이를 신중하게 관리하지 않으면, 비효율적으로 관리되어 조각화와 중복된 값이 이 RAM을 크게 차지할 수 있어 배치 크기가 줄어들게 됩니다.
이번 글에서는 대규모 언어 모델을 높은 처리량으로 처리할 때 주의해야 할 메모리 관리 문제와 관련이 있습니다.
연구자들은 이 문제에 대한 해결책으로 전통적인 가상 메모리와 페이징 기술에서 영감을 받은 어텐션 알고리즘인 PagedAttention을 제안했습니다. 또한, 메모리 사용을 더 줄이기 위해 연구자들은 vLLM을 배포했었죠. 이 LLM 서빙 시스템은 KV 캐시 메모리에서 거의 버려지는 캐시가 없게 하고 요청 내부와 사이에서 KV 캐시를 유연하게 공유하게 합니다.
vLLM은 PagedAttention을 사용하여 어텐션 키와 값들을 관리합니다. 모델 아키텍처에 어떠한 변경도 필요하지 않으면서 HuggingFace Transformers보다 최대 24배 더 많은 처리량을 제공합니다.

모델이 클수록 더 큰차이가 납니다. 이는 더 큰 모델이 더 많은 메모리를 필요로 하며 따라서 메모리 단편화의 영향을 더 많이 받기 때문일 것입니다.
전반적으로, vLLM은 Hugging Face Transformers 라이브러리보다 최대 24배 더 빠릅니다.
전통적인 어텐션 알고리즘과는 달리, vLLM은 비연속적인 메모리 공간에서 지속적인 키와 값 저장을 허용한다.
PagedAttention은 각 시퀀스의 Key-Value 캐시를 블록으로 나누고, 각 블록은 미리 결정된 길이의 토큰에 대한 키와 값으로 구성됩니다.
이 블록들은 Attention 계산 중에 PagedAttention 커널에 의해 효율적으로 식별됩니다.
블록들이 반드시 연속적일 필요가 없으므로, 키와 값들을 유연하게 관리할 수 있습니다.
프롬프트 "the cat is sleeping in the kitchen and the dog is"에 대한 PagedAttention. 어텐션 계산을 위한 텐서의 Key-Value 쌍은 가상의 연속 블록에 저장되며, 이는 GPU 메모리 내의 비연속 블록에 매핑됩니다.
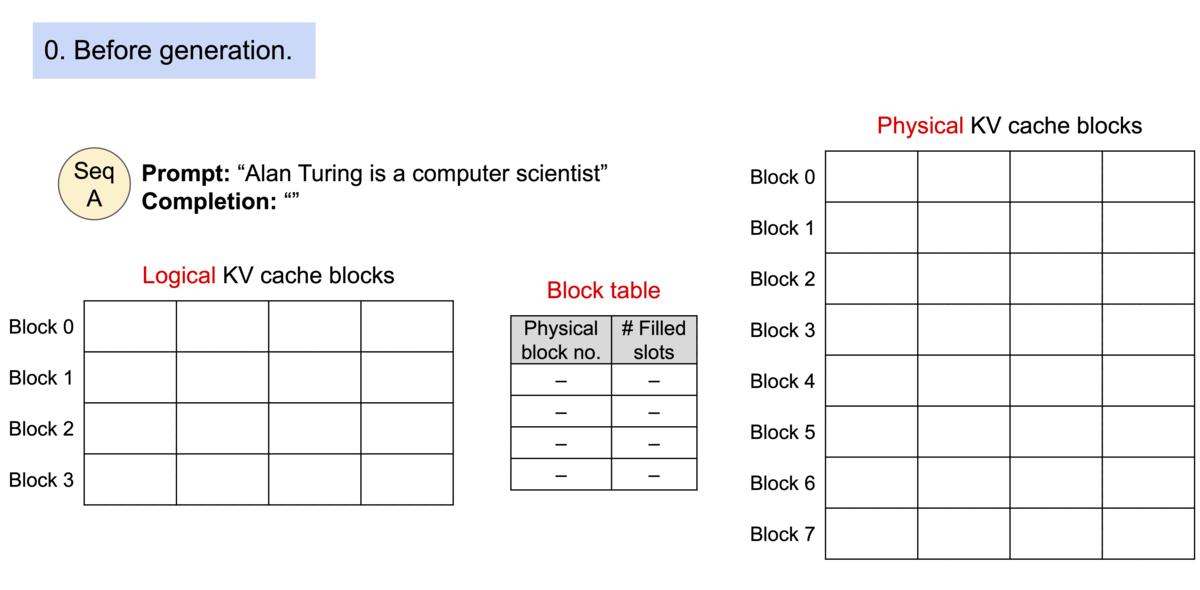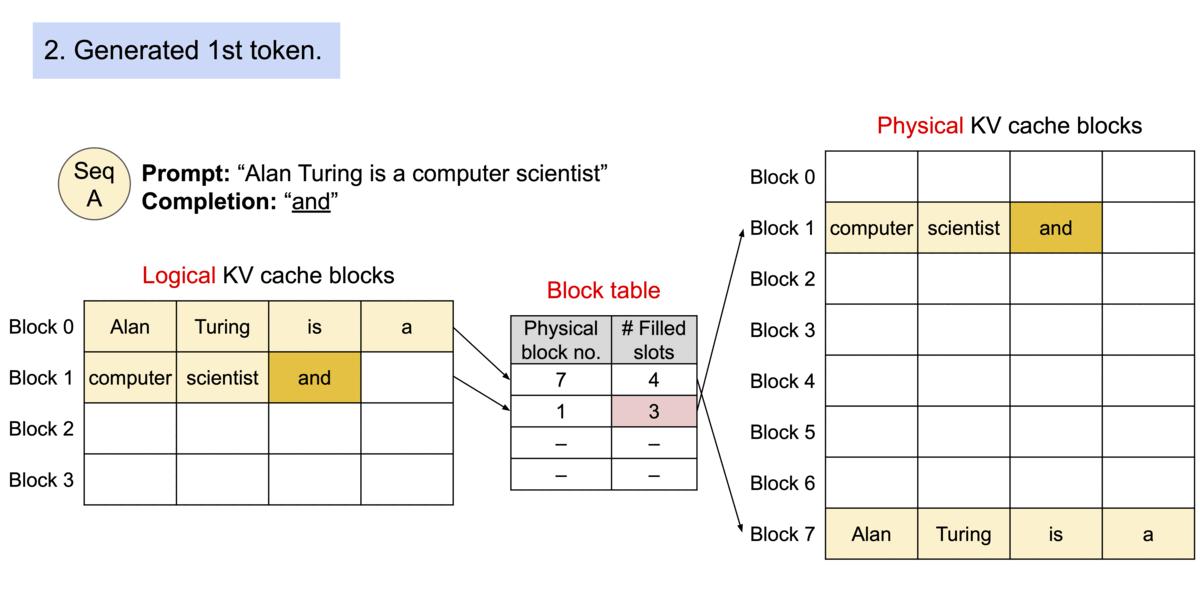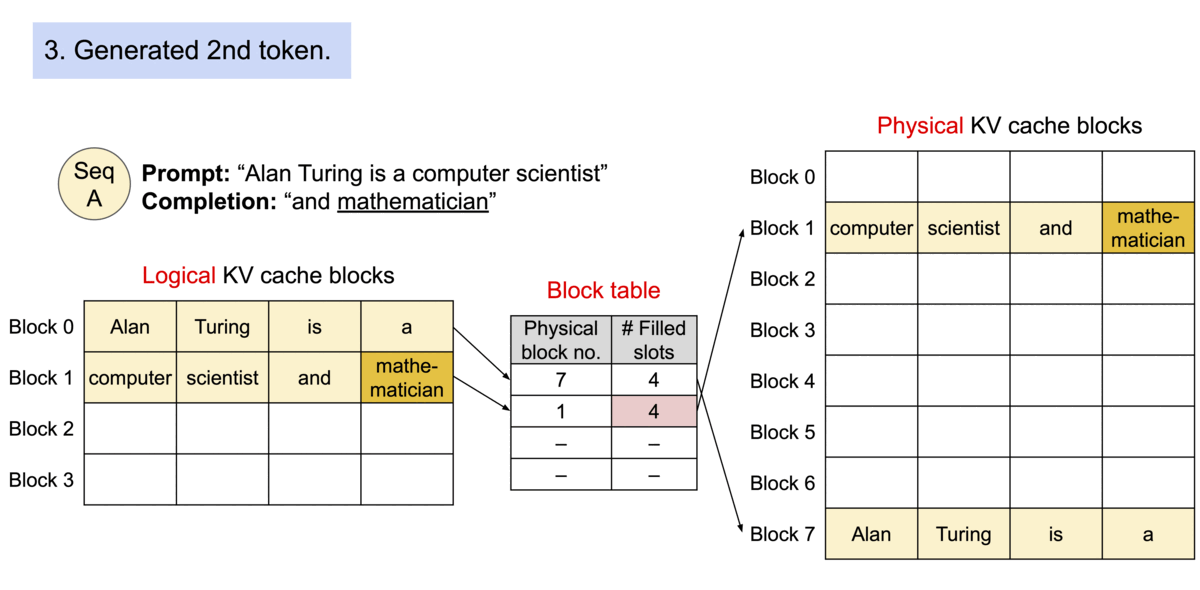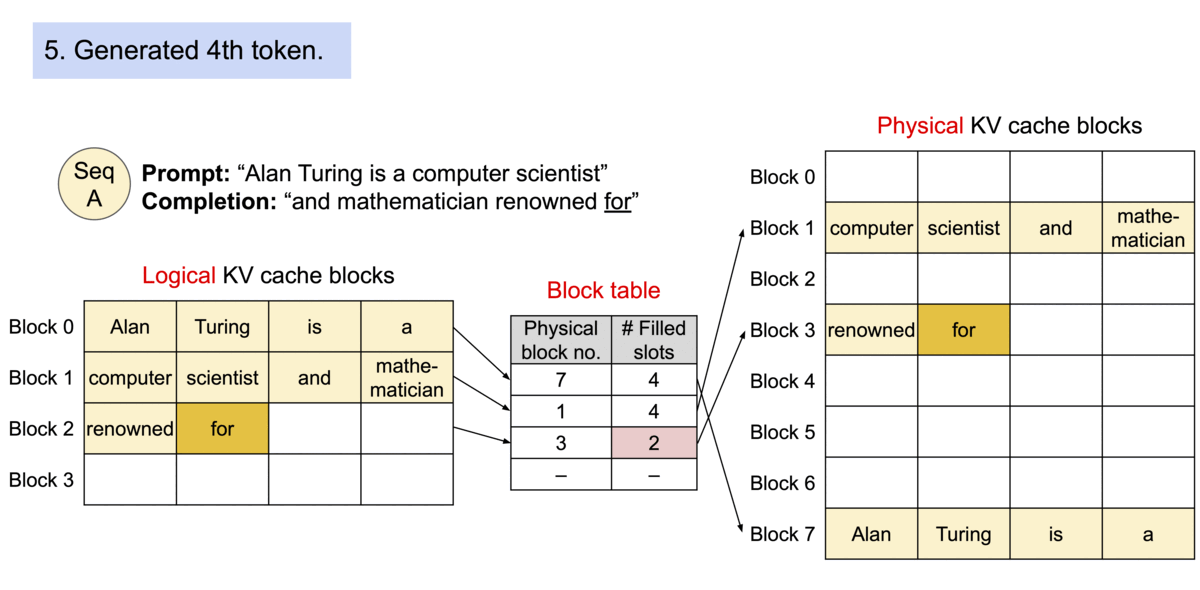
메모리 상에서 블록들이 "연속적일 필요가 없기 때문에", 운영체제의 가상 메모리처럼 키와 값을 더 유연하게 관리할 수 있습니다. 블록을 페이지로, 토큰을 바이트로, 그리고 시퀀스를 프로세스로 생각할 수 있습니다. 시퀀스의 연속적인 논리적 블록은 블록 테이블을 통해 비연속적인 물리적 블록으로 매핑됩니다. 물리적 블록은 새로운 토큰이 생성될 때마다 필요에 따라 할당됩니다.

참 쉽죠?
Static batching (Original Attention) vs Continous batching (Paged Attention)
PagedAttention에서 메모리 낭비는 시퀀스의 마지막 블록에서만 발생합니다. 실제로 이는 거의 최적의 메모리 사용률을 가져다주며, 낭비되는 메모리는 4% 미만입니다. 이러한 메모리 효율성의 향상은 매우 유용하게 작용합니다: 시스템이 더 많은 시퀀스를 함께 배치할 수 있게 되어 GPU의 사용률을 높이고, 따라서 위에서 보여진 성능 결과처럼 처리량을 크게 증가시킵니다.
Shared Memory
PagedAttention에는 또 다른 중요한 장점이 있습니다: 효율적인 메모리 공유입니다. 예를 들어, 병렬 샘플링에서는 동일한 프롬프트로부터 여러 출력 시퀀스가 생성됩니다. 이 경우에, 프롬프트에 대한 계산과 메모리는 출력 시퀀스 간에 공유될 수 있습니다. (한번 생성한 겹치는 부분이 있다면 운이 좋으면 다시 계산할 필요가 없다. )

PagedAttention의 메모리 공유 기능은 병렬 샘플링과 빔 서치(beam search)와 같은 복잡한 샘플링 알고리즘의 메모리 오버헤드를 크게 줄입니다, 그 메모리 사용량을 최대 55%까지 줄일 수 있습니다. 이것은 처리량에서 최대 2.2배의 향상을 가져올 수 있습니다. 이로 인해 이러한 샘플링 방법들이 LLM 서비스에서 실용적으로 사용될 수 있게 됩니다.
사용법
pip install vllmfrom vllm import LLM
prompts = ["Hello, my name is", "The capital of France is"] # Sample prompts.
llm = LLM(model="lmsys/vicuna-7b-v1.3") # Create an LLM.
outputs = llm.generate(prompts) # Generate texts from the prompts.
고작 이정도로 속도가 빨라진다고?
Custom model
- 모델 코드 가져오기
- HuggingFace Transformers 저장소에서 PyTorch 모델 코드를 클론하고 이를 vllm/model_executor/models 디렉토리에 넣습니다.
- 모델 코드에서 Forward methods 다시 쓰기
- 훈련에 사용된 코드 등 불필요한 코드는 삭제하세요
- 입력 파라미터 변경해줍니다.
- input_ids와 positions이 이제 flatten 된 텐서라는 점을 고려하여 코드를 업데이트하세요.
- 어텐션 연산(attention operation)을 모델의 아키텍처에 따라 GPTPagedAttention 또는 GPTNeoXPagedAttention으로 교체하세요.
def forward(
self,
input_ids: torch.Tensor,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[List[torch.FloatTensor]] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- labels: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
-) -> Union[Tuple, CausalLMOutputWithPast]:
+ positions: torch.Tensor,
+ kv_caches: List[KVCache],
+ input_metadata: InputMetadata,
+ cache_events: Optional[List[torch.cuda.Event]],
+) -> SamplerOutput:현재 vLLM은 기본 다중 헤드 주의 메커니즘(multi-head attention mechanism)과 RoPE임베딩(rotary positional embeddings)을 이용한 변형을 지원합니다. 만약 당신의 모델이 다른 주의 메커니즘을 사용한다면, vLLM에서 새로운 어텐션 계층(attention layer)을 구현해야 할 것입니다.
3. (선택사항) 텐서 병렬성 지원 구현
만약 당신의 모델이 단일 GPU에 맞지 않을 경우, 텐서 병렬성을 사용하여 관리할 수 있습니다. 이를 위해 모델의 선형 및 임베딩 계층을 그들의 텐서-병렬 버전으로 대체하세요. 임베딩 계층의 경우, 단순히 nn.Embedding을 VocabParallelEmbedding으로 대체하면 됩니다. 선형 계층의 경우, RowParallelLinear 또는 ColumnParallelLinear 중 하나를 사용해야 합니다. 일반적으로, ColumnParallelLinear는 QKV 선형 계층과 MLP 블록의 첫 번째 선형 계층에 사용되고 나머지 선형 계층에는 RowParallelLinear가 사용됩니다.
4. 가중치 로드 로직 구현
이제 당신은 *ForCausalLM 클래스에서 load_weights 메서드를 구현해야 합니다. 이 메서드는 HuggingFace의 체크포인트 파일에서 가중치를 로드하고 모델의 해당 계층에 할당해야 합니다. 대부분의 계층에 대해서는 과정이 간단하지만, 텐서-병렬 계층은 여러 GPU에 가중치를 분할해야 하므로 추가적인 주의가 필요합니다.
5. 모델 등록
마지막으로, 당신의 *ForCausalLM 클래스를 vllm/model_executor/models/__init__.py에 포함시키고, 이를 vllm/model_executor/model_loader.py의 _MODEL_REGISTRY에 등록하세요.

Reference
https://www.anyscale.com/blog/continuous-batching-llm-inference